SQL执行计划介绍
SQL执行计划概述
SQL执行计划是一个节点树,显示Vastbase执行一条SQL语句时执行的详细步骤。每一个步骤为一个数据库运算符。
使用EXPLAIN命令可以查看优化器为每个查询生成的具体执行计划。EXPLAIN给每个执行节点都输出一行,显示基本的节点类型和优化器为执行这个节点预计的开销值。如图所示。
最底层节点是表扫描节点,它扫描表并返回原始数据行。不同的表访问模式有不同的扫描节点类型:顺序扫描、索引扫描等。最底层节点的扫描对象也可能是非表行数据(不是直接从表中读取的数据),如VALUES子句和返回行集的函数,它们有自己的扫描节点类型。
如果查询需要连接、聚集、排序、或者对原始行做其它操作,那么就会在扫描节点之上添加其它节点。 并且这些操作通常都有多种方法,因此在这些位置也有可能出现不同的执行节点类型。
第一行(最上层节点)是执行计划总执行开销的预计。这个数值就是优化器试图最小化的数值。
执行计划显示信息
除了设置不同的执行计划显示格式外,还可以通过不同的EXPLAIN用法,显示不同详细程度的执行计划信息。常见有如下几种,关于更多用法请参见12.19.86EXPLAIN语法说明。
EXPLAIN statement:只生成执行计划,不实际执行。其中statement代表SQL语句。
EXPLAIN ANALYZE statement:生成执行计划,进行执行,并显示执行的概要信息。显示中加入了实际的运行时间统计,包括在每个规划节点内部花掉的总时间(以毫秒计)和它实际返回的行数。
EXPLAIN PERFORMANCE statement:生成执行计划,进行执行,并显示执行期间的全部信息。
为了测量运行时在执行计划中每个节点的开销,EXPLAIN ANALYZE或EXPLAIN PERFORMANCE会在当前查询执行上增加性能分析的开销。在一个查询上运行EXPLAIN ANALYZE或EXPLAIN PERFORMANCE有时会比普通查询明显的花费更多的时间。超支的数量依赖于查询的本质和使用的平台。
因此,当定位SQL运行慢问题时,如果SQL长时间运行未结束,建议通过EXPLAIN命令查看执行计划,进行初步定位。如果SQL可以运行出来,则推荐使用EXPLAIN ANALYZE或EXPLAIN PERFORMANCE查看执行计划及其实际的运行信息,以便更精准地定位问题原因。
详解
如10.4.2.1SQL执行计划概述节中所说,EXPLAIN会显示执行计划,但并不会实际执行SQL语句。EXPLAIN ANALYZE和EXPLAIN PERFORMANCE两者都会实际执行SQL语句并返回执行信息。在这一节将详细解释执行计划及执行信息。
执行计划
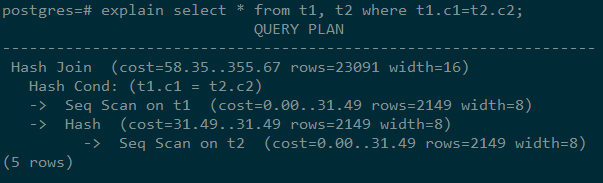
以如下SQL语句为例:
SELECT * FROM t1, t2 WHERE t1.c1 = t2.c2;
执行EXPLAIN的输出为:
执行计划层级解读(自下而上纵向):
- 第一层:Seq Scan on t2
表扫描算子,用Seq Scan的方式扫描表t2。这一层的作用是把表t2的数据从buffer或者磁盘上读上来输送给上层节点参与计算。
- 第二层:Hash
Hash算子,作用是把下层计算输送上来的算子计算hash值,为后续hash join操作做数据准备
- 第三层:Seq Scan on t1
表扫描算子,用Seq Scan的方式扫描表t1。这一层的作用是把表t1的数据从buffer或者磁盘上读上来输送给上层节点参与hash join计算。
- 第四层:Hash Join
join算子,主要作用是将t1表和t2表的数据通过hash join的方式连接,并输出结果数据
执行计划中的关键字说明:
- 表访问方式
Seq Scan
全表顺序扫描。
Index Scan
优化器决定使用两步的规划:最底层的规划节点访问一个索引,找出匹配索引条件的行的位置,然后从下层索引匹配的行位置读取上层表中的那些行。独立地抓取数据行比顺序地读取它们的开销高很多,但是因为并非所有表的页面都被访问了,这么做实际上仍然比一次顺序扫描开销要少。使用两层规划的原因是,上层规划节点在读取索引标识出来的行位置之前,会先将它们按照物理位置排序,这样可以最小化独立抓取的开销。
如果在WHERE里面使用的好几个字段上都有索引,那么优化器可能会使用索引的AND或OR的组合。但是这么做要求访问两个索引,因此与只使用一个索引,而把另外一个条件只当作过滤器相比,这个方法未必是更优。
索引扫描可以分为以下几类,他们之间的差异在于索引的排序机制。
- Bitmap Index Scan
使用位图索引抓取数据页。
- Index Scan using index_name
当使用简单的索引搜索,会使用索引的顺序去获取表行数据,这会使得读取这些数据的开销更大。而当前的数据行比较少,因此额外的行位置排序操作是没有价值的。最常用的方法是只获取一行数据去查看这类计划,并且那些查询是需要使用ORDER
BY条件去匹配索引顺序的。当使用这种方法,为了满足ORDER
BY,就可以省去冗余的排序步骤。表连接方式
Nested Loop
嵌套循环,适用于被连接的数据子集较小的查询。在嵌套循环中,外表驱动内表,外表返回的每一行都要在内表中检索找到它匹配的行,因此整个查询返回的结果集不能太大(不能大于10000),要把返回子集较小的表作为外表,而且在内表的连接字段上建议要有索引。
(Sonic) Hash Join
哈希连接,适用于数据量大的表的连接方式。优化器使用两个表中较小的表,利用连接键在内存中建立hash表,然后扫描较大的表并探测散列,找到与散列匹配的行。Sonic和非Sonic的Hash Join的区别在于所使用hash表结构不同,不影响执行的结果集。
Merge Join
归并连接,通常情况下执行性能差于哈希连接。如果源数据已经被排序过,在执行融合连接时,并不需要再排序,此时融合连接的性能优于哈希连接。
- 运算符
sort
对结果集进行排序。
filter
EXPLAIN输出显示WHERE子句当作一个”filter”条件附属于顺序扫描计划节点。这意味着规划节点为它扫描的每一行检查该条件,并且只输出符合条件的行。预计的输出行数降低了,因为有WHERE子句。不过,扫描仍将必须访问所有10000 行,因此开销没有降低;实际上它还增加了一些(确切的说,通过10000 * cpu_operator_cost)以反映检查WHERE条件的额外CPU时间。
LIMIT
LIMIT限定了执行结果的输出记录数。如果增加了LIMIT,那么不是所有的行都会被检索到。
执行信息
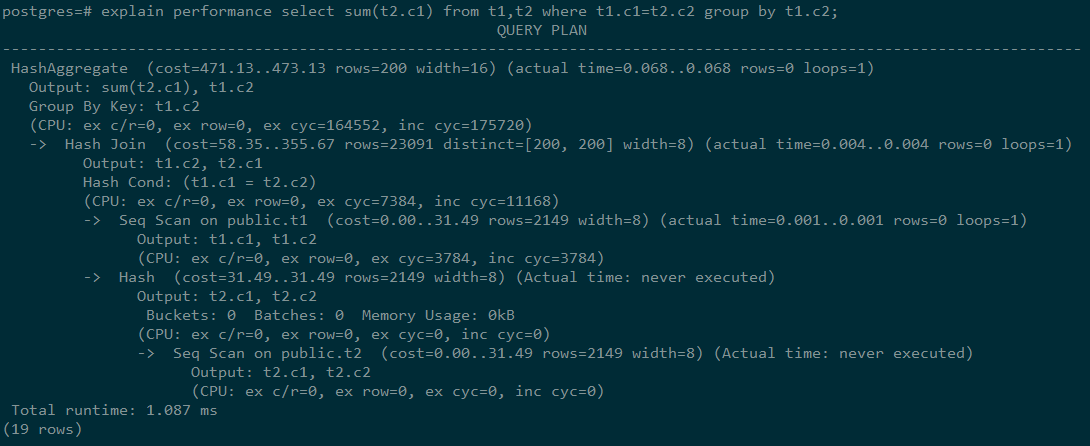
以如下SQL语句为例:
select sum(t2.c1) from t1,t2 where t1.c1=t2.c2 group by t1.c2;
执行EXPLAIN PERFORMANCE输出为: